นับจำนวน unique views ด้วย HyperLogLog
ลองจินตนากาลดูว่า ถ้าเราทำ social media app แล้วอยากโชว์ที่ใต้ video ว่ามีจำนวน unique views ที่เข้ามาดูกี่คน เราจะทำยังไง? โดยที่ user คนหนึ่งอาจจะดูซ้ำได้หลายครั้ง เราต้องไม่นับซ้ำ
เราสามารถทำแบบง่ายๆได้ด้วยการเก็บทุก record ของ user_id ทั้งหมดที่เคยเข้ามาดูเอาไว้ อาจจะใช้ relational database ก็ได้ แล้วเราก็แค่ SELECT DISTINCT COUNT(user_id) FROM views หรือถ้าเราใช้ Redis เราอาจจะเก็บ user_id ลง set แทน แล้วเราก็แค่ SCARD users_set ก็จะได้จำนวนของใน set แล้ว แต่ว่าข้อเสียของวิธีง่ายๆแบบนี้ก็คือเปลืองที่ เพราะเราต้องจำ user_id ทั้งหมด เพื่อเอาไว้เช็คว่ามันซ้ำไหม ทั้งที่ requirement จริงๆ เราแค่อยากรู้จำนวน unique user views ไม่ได้อยากรู้ว่ามีใครบ้าง
ถ้าเราลด requirement ของเราลงมาซํกหน่อย เป็นอยากรู้จำนวน unique views คร่าวๆ ไม่ต้องเป๊ะก็ได้ แต่ขอให้ใช้ memory น้อยลงหน่อย เราสามารถใช้สิ่งที่เรียกว่า probabilistic data structure เข้ามาช่วยได้
ตัวอย่างเช่น Linear Counting วิธีการก็คือ เราจะสร้าง bit array ที่เป็น 0 ทั้งหมดไว้ก่อน แล้วเอา user_id เข้า hash function แล้วไปตกช่องไหนก็เปลี่ยนจาก 0 เป็น 1 เอาไว้ แล้วสุดท้ายเราก็แค่นับว่ามี 1 กี่ตัว ก็ได้เป็นจำนวน unique user views แล้ว เพราะตัวที่ซ้ำ พอ hash แล้วมันจะไปตกช่องเดิม วิธีนี้ฉลาดสุดๆไปเลย เพราะเปลืองที่น้อยลงมาก แต่ว่าจะนับผิดได้บ้างถ้าเกิด collision โดยเราสามารถ trade-off ได้ด้วยการ ใช้ bit array ที่ใหญ่หน่อย เช่น ใหญ่กว่าจำนวน users ทั้งหมด
แต่ว่าถ้าจำนวน users เยอะมากๆ ยังมีอีกวิธีที่ประหยัดที่ได้มากสุดๆก็คือ HyperLogLog วิธีการก็คือ เราจะจำแค่ว่า จาก hash(user_id) ที่เคยเห็นมา เจอ leading zero ยาวสุดกี่ตัว ถ้าผ่านตามาทั้งหมด เจอยาวสุด n ตัว แปลว่าเราต้องไล่ดูมาแล้วอย่างน้อย 2^n คน ฉลาดสุดๆไปเลย!
แต่จะเห็นว่า ยิ่ง n เยอะ range มันจะยิ่งกว้าง กับถ้าเกิดบังเอิญโชคดีเจอ user แรก ก็มี hash(user_id) ที่มี 0 ติดกัน 5 ตัว แล้ว เราก็จะประมาณผิดไปมากๆ ถึงแม้โอกาสจะน้อย แต่ก็เป็นไปได้ ดังนั้นใน algorithm จริงจะมีรายละเอียดมากกว่านี้ เพื่อให้ accurary ของค่าประมาณดีขึ้น หลักการคร่าวๆก็คือ เราก็ทำมันหลายๆรอบหน่อย แล้วเอามาหาค่าเฉลี่ย
ข่าวดีคือ ถ้าใช้ Redis มัน implement probabilistic data structures มาให้แล้วหลายตัว เราเลือกใช้ได้เลยสบายๆ
เรามาลองใช้ HyperLogLog กันด้วย Python
import redis
r = redis.Redis(host='localhost', port=6379, db=0)
def test_hll_accuracy(cardinality):
key = "hll_test"
r.delete(key)
for i in range(cardinality):
r.pfadd(key, 'salt123' + str(i))
estimated_cardinality = r.pfcount(key)
absolute_error = abs(estimated_cardinality - cardinality)
relative_error = 100 * absolute_error / cardinality if cardinality > 0 else 0
return estimated_cardinality, relative_error
cardinalities = [1, 5, 10, 50, 100, 500, 1000, 5000,
10000, 50000, 100000, 500000, 1000000]
relative_errors = []
estimated_cardinalities = []
for cardinality in cardinalities:
estimated, relative_error = test_hll_accuracy(cardinality)
relative_errors.append(relative_error)
estimated_cardinalities.append(estimated)
r.delete("hll_test")
เราลอง plot graph ดูจะเห็นว่า estimate ได้ใกล้ค่าจริงมากเวอร์ 😮
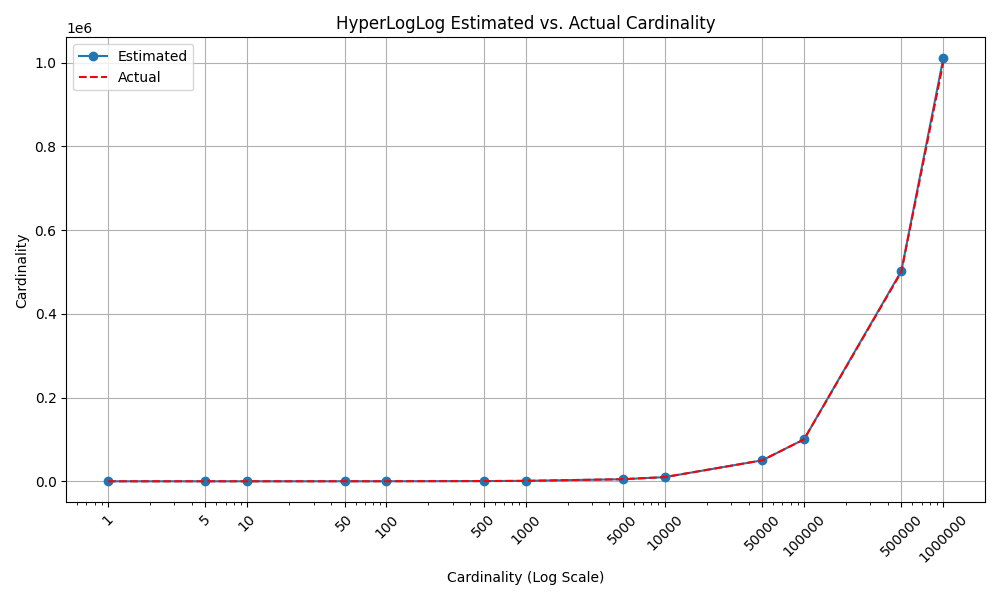
import matplotlib.pyplot as plt
plt.figure(figsize=(10, 6))
plt.plot(cardinalities, estimated_cardinalities, marker='o', linestyle='-', label="Estimated")
plt.plot(cardinalities, cardinalities, linestyle='--', label="Actual", color='red')
plt.xscale('log')
plt.xlabel('Cardinality (Log Scale)')
plt.ylabel('Cardinality')
plt.title('HyperLogLog Estimated vs. Actual Cardinality')
plt.grid(True)
plt.xticks(cardinalities, [str(c) for c in cardinalities], rotation=45)
plt.legend()
plt.tight_layout()
plt.show()
ลองดู relative error ก็จะเห็นว่าเป็นไปตามที่เค้าว่า คือ ไม่เกิน 2% 👍
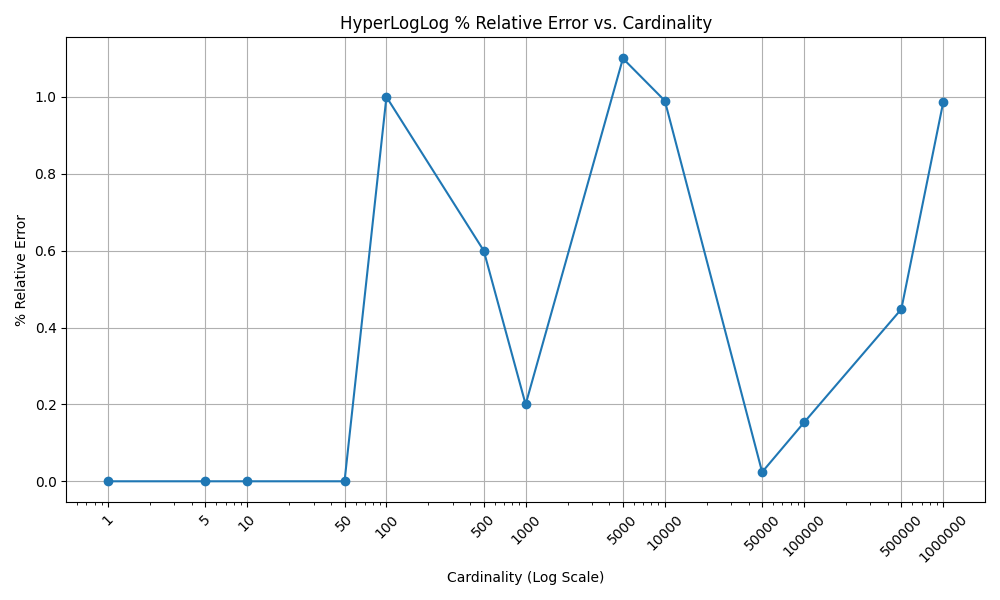
plt.figure(figsize=(10, 6))
plt.plot(cardinalities, relative_errors, marker='o', linestyle='-')
plt.xscale('log')
plt.xlabel('Cardinality (Log Scale)')
plt.ylabel('Relative Error')
plt.title('HyperLogLog Relative Error vs. Cardinality')
plt.grid(True)
plt.xticks(cardinalities, [str(c) for c in cardinalities], rotation=45)
plt.tight_layout()
plt.show()